
Het team
 |
 |
 |
 |
Op 17-11-2019 begonnen wij aan het project voor NSI. We begonnen het project met 5 teamleden, Guido Visser als project leider, Thijs Nieuwdorp als product owner en Rienk Koenders, Max Taylor en Jaap Wijnen als developers.
Het doel van het project was als volgt:
Werk met GPS data van treinen om te kijken of daar mee een model gemaakt kan worden om vertraging te voorspellen.
De relevantie hiervan voor NSI is dat ze hiermee onafhankelijk kunnen worden van de opgegeven vertragingen van internationale partijen. Door de GPS uit te meten via de telefoon van reizigers zelf en dit te gebruiken om te kijken of een trein op tijd rijdt kan er door NSI een betere service geleverd worden dan concureerende partijen.
De initiele data¶
Initieel begonnen we het project met deze data. Toen we de initiele data verkening begonnen waren we gaan kijken naar wat de data inhield.
Eerst waren we gaan kijken naar hoe het traject liep, of we al eigenaardigeheden konden vinden en of we al iets zinnigs konden zeggen over de data.
Hier kwam onder andere uit, dat de gps punten zich niet enkel op het traject zelf bevinden. Op sommige locaties vallen de punten buiten het traject, zo worden er punten voorbij Amsterdam Centraal weergeven. Dit komt volgens ons doordat de trein af en toe voor onderhoud naar een depot moet gaan.
Toen we gingen nadenken over hoe we eventueel vertraging konden voorspellen constateerde we al snel dat onze huidige data niet toerijkend was. Om iets te kunnen zeggen over vertraging moeten we de GPS data kopellen aan bijbehorende plannings data.
Thijs is voor ons binnen NSI op zoek gegaan naar de plannings data en een manier om deze te kopellen met de realisatie data. Drie weken later ontvingen we na een kleine pauze van het project de data
De nieuwe data¶
We kregen van NSI vervolgens twee extra data sets, de planning en de kopelling data.
Deze data geeft ons twee extra zaken - namelijk plannings data waartegen we de GPS punten kunnen plaatsen en een tabel waar zowel het materiaal nummer en het treinnummer in staan om op die manier de planning met de realisatie data te kunnen kopellen.
Bevindingen uit de data¶
Discrepantie volgnummers¶
Volgnummers in onze dataset geven voor een specifieke rit van bijvoorbeeld Amsterdam naar Brussel aan op welk punt in de rit ze zitten. In ons voorbeeld Rit zal Amsterdam volgnummer 1 hebben en zal Schiphol volgnummer 2 hebben. We kwamen er na onderzoek achter dat de volgnummers niet altijd liepen zoals wij verwachten.

Zoals te zien komt komen onder andere 14 en 15 significant vaker voor dan volgnummer 1. Dit is erg raar aangezien een volgnummer van een trein altijd zou moeten volgen op een eerder volgnummer. Na verder onderzoek zijn we gaan onderzoeken hoe dit kwam.
Onze hypothese was dat het kwam doordat als een trein opgeheven wordt en vervolgens weer vervolgd wordt dat de trein dan een aantal volgnummers overslaat. Toen we dit gingen testen door alle opgeheven treinen uit de dataset te halen bleek het inderdaad zo dat hierna de volgnummers weer lopen zoals verwacht.

Voor ons is het van belang dat de volgnummers kloppen - als dit niet zo is zou het dus in de dataset voor kunnen komen dat een rit niet goed loopt. Als de rit niet goed loopt zouden er fouten kunnen ontstaan in hoe we voor een traject de vertraging voorspellen.
Meerdere trajecten¶
Van Asd naar Brusz 343, (Amsterdam - Brussel)
Van Brusz naar Asd 350, (Brussel - Amsterdam)
Van Gv naar Brusz 82, (Den Haag - Brussel)
Van Brusz naar Gv 80, (Brussel - Den Haag)
Van Rtd naar Brusz 67, (Rotterdam - Brussel)
Van Brusz naar Rtd 64, (Brussel - Rotterdam)
Van Asd naar Esn 1,
Van Shl naar Brusz 1
Als we kijken naar hoe de trajecten verlopen in onze dataset welke eigenlijk enkel het traject Amsterdam Brussel moet bevatten zien we dat er ook 6 andere trajecten in voorkomen, waarvan twee maar een enkele keer.
Lege Entries¶
Gedurende het project hebben er in de datasets vrij wat lege entries gezeten. Aan het begin van het project hebben wij onderzocht wat hiervoor de oorzaak was. Om erachter te komen wat de redenen zijn voor de lege entries van de data moeten we bij het begin beginnnen. Hieronder zie je een lijstje van alle kolommen in de oorspronkelijke dataset, en per kolom hoeveel van de rijen een lege waarde bevat in die kolom.
Je ziet hier dat er aan het begin dus 11860 entries leeg waren. Wat meteen opvalt is dat alle waardes die leeg zijn iets met tijd te maken hebben. Het zijn allemaal timestamp formats.
Er is een mooie verklaring voor deze lege entries:
Er zijn twee situaties. De trein is opgeheven of de trein is niet opgeheven. Deze tellen op tot alle missende entries in de data (2550 + 830 = 3380).
Bij de opgeheven treinen is er missende data voor de kolommen ta_aplan_dt, ta_uitvtijd_dt, ta_oplan_verschiltijd_n en ta_aplan_verschiltijd_n. Al deze missende data is te verklaren doordat de treinen opgeheven zijn.
De treinen met missende entries maar die niet opgeheven zijn, zijn interessant. Er zijn maar twee kolommen die leeg zijn: ta_oplan_dt en ta_oplan_verschiltijd_n. De laatste is leeg omdat deze afgeleid is van de eerste. Dus de vraag is waarom is de eerste leeg? In andere woorden; waarom hadden deze treinen geen orignele planning. Hoogstwaarschijnlijk komt dat omdat deze treinen extra ingezet zijn.
Na de koppeling¶
Met de lege entries tot nu toe konden we dus niet zoveel doen. Vervolgens hebben wij dit in een pandas Dataframe met eigen format gezet. Daar kwam het volgende uit qua lege entries:
Hier zie je dat het aantal lege entries een stuk meer is. Dit komt omdat wij bij het genereren van deze Dataframe al gegroepeerd hebben op de verschillende ritten die in de planning dataset stonden. Binnen deze ritten zaten ook weer een aantal fouten. Dit heeft te maken met een aantal dingen:
- Wanneer twee opeenvolgende planning 'rijen' van de dataset niet hetzelfde treinnummer bevatten zal deze worden gezien als foutieve data
- Wanneer twee planning 'rijen' van de dataset niet op hetzelfde traject / tussen de zelfde dienstregelpunten zit zal deze worden gezien als foutieve data.
- Wanneer er een fout zit in de volgorde tussen het aankomen en het vertrekken van een bepaalde plek, zal deze entry een waarde krijgen van 'NaN' in de bijbehorende kolommen.
Dit verklaart al waarom er zoveel extra lege rijen bij zijn gekomen. Wanneer er bijvoorbeeld een treinnummer verkeerd is ingevoerd en deze niet te linken is aan andere ritten van dit treinnummer, zal er voor deze plannings entry op de verschillende kolommen een lege waarde worden ingevoerd.
In de andere datasets leek er geen geval te zijn van foutieve data. De lege entries in die datasets waren allemaal te verklaren. Door deze koppeling konden we uiteindelijk dus met een stuk minder data aan de slag. Hierdoor konden we wel makkelijker zien welke ritten bij elkaar horen, op welk traject deze zich bevindt en welke planning/realisatie logs hierbij horen. Wanneer er uiteindelijk meer data wordt toegevoegd van meerdere maanden zal de effectiviteit dan ook toenemen.
Discrepantie tussen a > v en v > a¶
Er is in 70 gevallen spraken van een discrepantie tussen a en v. In de dataset zou A altijd moeten volgen op V en andersom zou V altijd moeten volgen op A. Je vertrekt immers altijd nadat je aankomt, of vice versa. Het bleek echter in 70 gevallen zo te zijn dat A A of V V voorkwam in de dataset.
Het blijkt dat bij alle 70 casusses het volgnummer ook niet goed loopt. De hypothese is dat de discrepantie tussen AV VA verklaard wordt door het inzetten van een nieuwe trein op zo'n manier wordt ingezet dat die een station overslaat & in de boeken dus twee keer vertrekt of twee keer aankomt.
Analyse op huidige vertraging¶
Als we kijken naar de vertragingen meegegeven in de dataset zien we dat vaak bij ongeveer het 25e volgnummer op het traject er veel vertraging wordt opgebouwd. Ook zien we dat de vertraging bijna nooit volledig wordt afgebouwd behalve als deze al erg laag was (lager dan 3 minuten).
Werkbaar maken data¶
Bij analyse van de nieuwe data zijn we gaan kijken naar hoe we dit konden omvormen naar een bepaalde format om er goed mee te kunnen werken. Dit hebben we uiteindelijk omgevormd naar een structuur die hieronder is te zien.
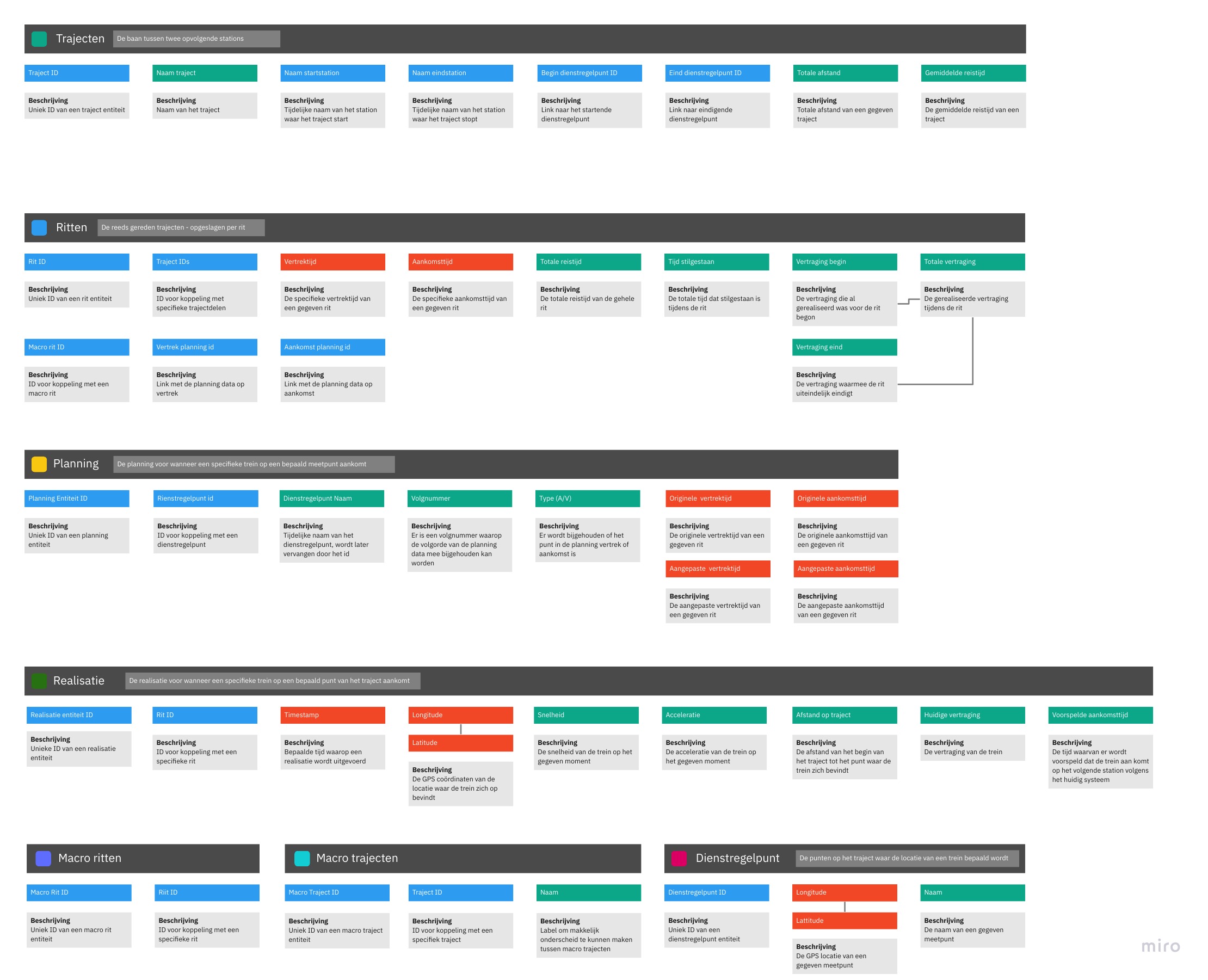
 |  |
We zijn aan de slag gaan om in pandas alle ruwe data om te vormen tot deze data set om er goed mee te kunnen werken.
De koppeling van de realisatie en ritten¶
Om de realisatie te kopellen met de ritten is het van belang dat we via de koppeling dataset de data koppelen. Dit doen we door uit de koppeling data het materiaal nummer te pakken en deze te kopellen aan een rit entiteit. Hieronder een voorbeeld van hoe de koppeling werkt met een rit entiteit.
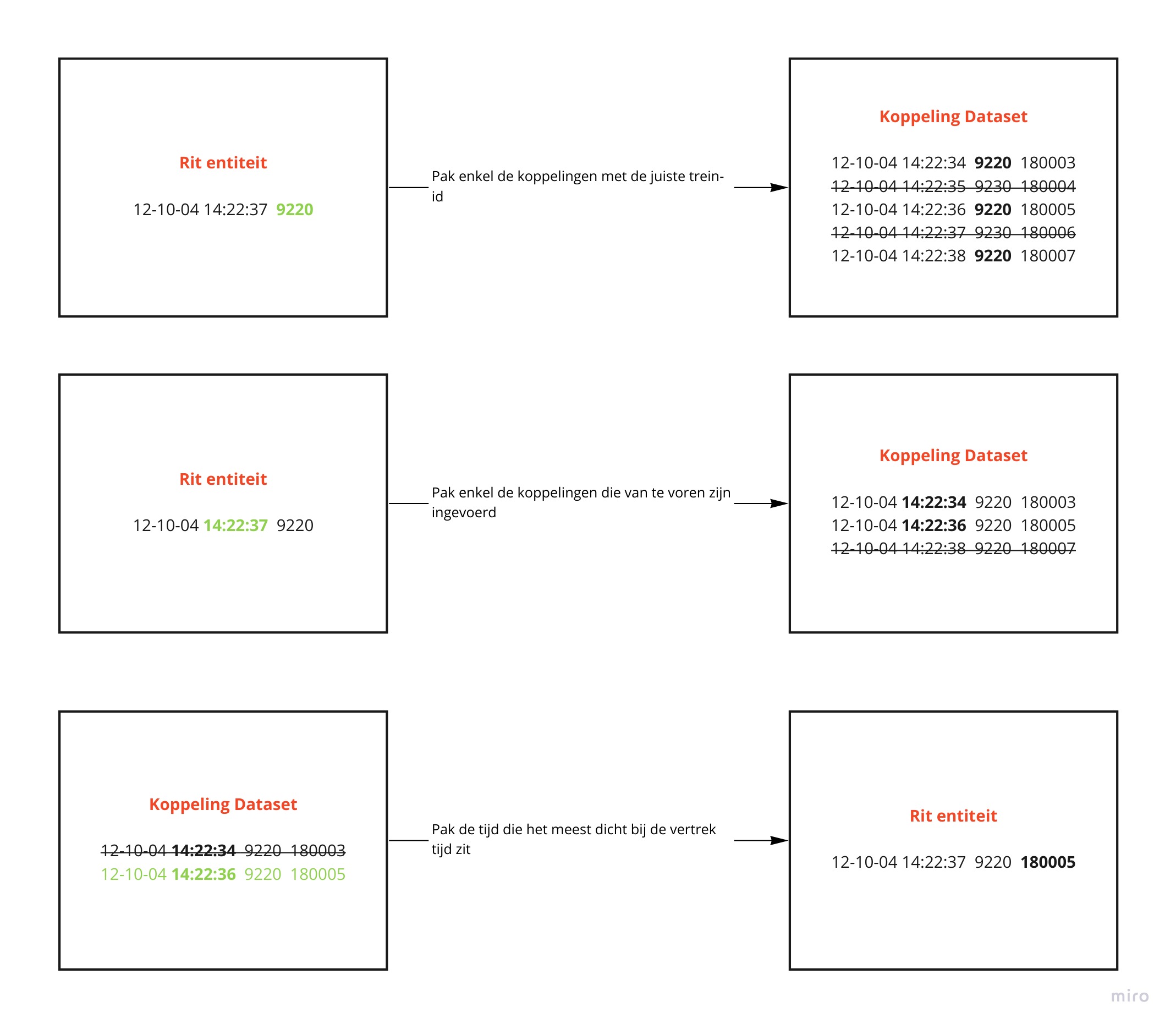
Dit materiaal nummer wat nu aan de rit entiteit is gekoppeld kunnenw we vervolgens gebruiken om de rit te kopellen aan de realisatie entiteiten.
Bevindingen koppeling¶
Toen we aan de slag gingen met de koppeling deden we een aantal bevindingen. Zo constateerde we dat de koppeling er nooit correct uit leek te komen. Toen we hier verder onderzoek naar deden bleken er twee dingen aan de hand te zijn.
- De realisatie tijd liep een uur vooruit op de plannings tijd.
- De realisatie timestamp data had een specifieke locatie codering waardoor het niet overeenkwam met de plannings timestamp data
Ondanks deze voorwaardes blijken veel ritten nog steeds niet te kloppen. Om dit te verbeteren stellen we als voorwaarde dat het verschil in uitvoertijd van de rit en invoertijd van het nummer niet meer dan 12 uur mag verschillen. Hierdoor filteren we 5000 van de 7000 ritten uit onze dataset maar lijkt de koppeling beter te werken.
Als we alle ritten van het Amsterdam Schiphol traject plot valt het op dat punten die buiten de juiste locatie geplot worden dan vaak wel consistent op specifieke locaties gefocust zijn. De veronderstelling is dat dit onder andere kan komen doordat als trein A op punt een weg rijdt van een specifieke locatie een tweede trein consistent ook weg rijdt van een bepaald locatie - en dat deze twee locaties in principe altijd hetzelfde zijn. De koppeling met het jusite trein/materiaal nummer gaat dus nog steeds niet altijd volledig goed zoals hieronder te zien.
Om toch de juiste ritten te kunnen selecteren om zo goed met de data aan de slag te kunnen gaan zijn we gaan kijken naar de gps punten om daaruit de juiste te kunnen selecteren. We pakken van elke rit het het gemiddelde gps punt. Zoals weergeven hieronder:
Zodra we alle gemiddeldes van alle ritten in een traject hebben rond ik de GPS punten af op een een minder exact GPS punt ofwel van 5.7834634348 naar 5.78, hierdoor overlapen meerdere GPS punten met elkaar.
Nu pakken we door middel van de modus van de GPS punten het punt waar de meeste GPS punten op een vallen. Hieronder is dat punt weergeven.
Vervolgens tekenen we een vierkant in een radius van 10 kilometer rond dat punt om een gebied te defineren zoals te zien is hieronder.
Alle ritten die binnen die radius vallen zijn in ons geval dus correcte ritten en alle ritten die er buiten vallen zijn niet juist gekoppeld.
Ik kan nu dus onderscheid maken tussen correcte koppelingen en foutieve koppelingen. Hierdoor kunnen we nu aan de slag gaan met de correcte koppeling om een voorspelling te gaan maken.
Afstand van een traject¶
Om te kunnen berekenen wat de kans is dat een trein te laat gekomen op een gegeven locatie op een traject, moeten we natuurlijk wel weten hoe lang dat traject in totaal is en hoeveel afstand de trein al heeft afgelegd op dat traject per GPS log. De afstanden berekenen we als volgt:
- Per traject zoeken we naar alle verbonden ritten
- Per rit zoeken we de bijbehorende realisatie entries op
- Deze realisatie entries sorteren we op tijd
Vervolgens maken we gebruik van de haversine formule om de afstand te berekenen tussen deze GPS entries. Vervolgens worden de totalen gesommeerd om de gemiddelde totale afstand op een bepaald traject te berekenen.
Over het algemeen lijkt dit redelijk accuraat te zijn. Er moeten echter nog wel een aantal dingen gebeuren voordat dit echt kloppend is. Ten eerste heeft dit te maken met het aantal GPS punten dat gelinkt is aan een traject. Zodra er meer data bij komt zou dit al stukken beter moeten werken. Daarnaast zouden we de verschillende dienstregelpunten nog kunnen implementeren en linken aan de datasets, zodat we meerdere accurate tussenstukjes hebben op een traject.
De voorspelling¶
In onze data set hebben we nu dus per punt de gereden afstand en de tijd dat een rit op dat gereden punt is. Met deze twee waardes kunnen we beginnen aan het eerste voorspel model. We doen dit aan de hand van een look-up table. Een tabel die gegeven op de x as de tijd en op de y as de afstand met behulp van de vertraging die al in de dataset zit kijkt wat de kans is of treinen op tijd komen.
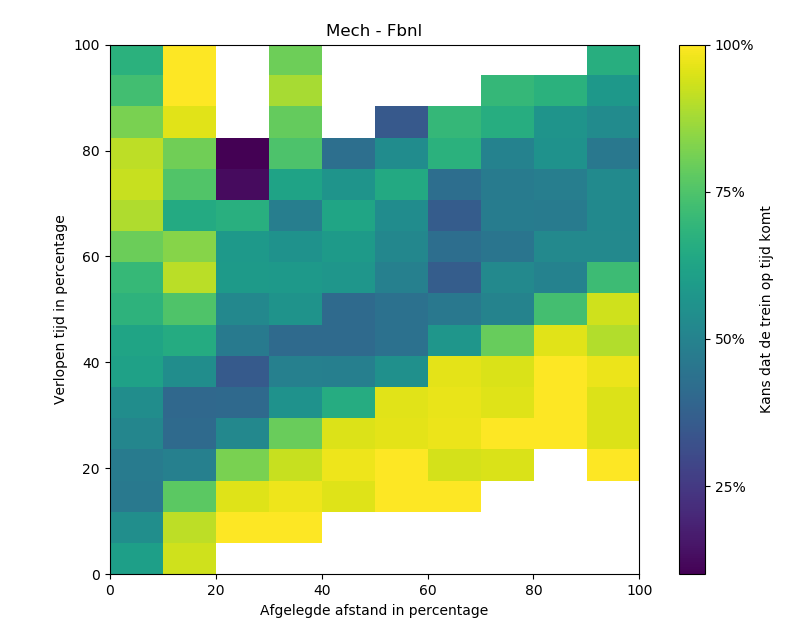
Hoe geler de kleur hoe groter de kans dat de rit wel op tijd op komt, hoe blauwer de kleur hoe kleiner de kans datde rit op tijd komt.
Hoe nu verder?¶
Hoewel we aan het begin van het project misschien verwacht hadden om wat verder te komen met de voorspellingen, zijn we toch wel blij met de basis die er nu staat. Veel van de tijd is gaan zitten in het ordenen, opschonen en koppelen van de verschillende datasets en wij denken dat met het huidige format van de data hier prima aan doorgewerkt kan worden.
Met de lookup tables zien we al dat er wat patronen zitten in de percentages van het te laat komen op verschillende afstanden op een traject. Dit geeft al duidelijk aan dat er zeker waarde zit in de GPS data. Een volgende stap zal waarschijnlijk zijn om met de huidige dataset betere en uitgebreidere voorspellingen te gaan doen; om zo nog meer te kunnen zeggen over de GPS data. Dit zou eventueel gedaan kunnen worden met een machine learning algoritme. Als deze modellen bewezen goed werken zou er gekeken kunnen worden naar het testen van het model bij gebruikers om deze later eventueel te implementeren.